
AI systems and large language models need to be trained on massive amounts of data to be accurate but they shouldn’t train on data that they don’t have […]

‘Adobe does not train Firefly Gen AI models on customer content’: Company responds to backlash
After outrage and confusion from Adobe users over a new policy update, Adobe clarifies its does not use their content to train its AI models.

Adobe users are outraged over vague new policy’s AI implications
Adobe has notified users of a new policy saying it can access user content to “improve its Services and Software.” Users are outraged that this might mean using their content to train AI.

AI training data has a price tag that only Big Tech can afford
Data is at the heart of today’s advanced AI systems, but it’s costing more and more — making it out of reach for all but the wealthiest tech […]
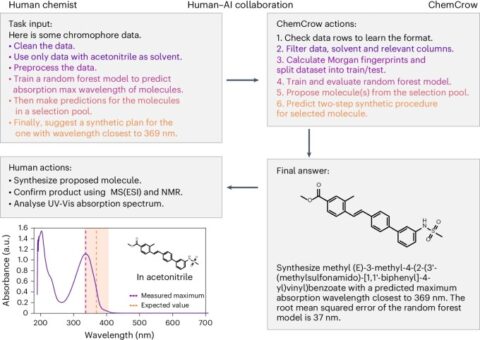
This Week in AI: OpenAI and publishers are partners of convenience
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in […]

Slack under attack over sneaky AI training policy
On the heels of ongoing issues around how big tech is appropriating data from individuals and businesses in the training of AI services, a storm is brewing among […]

Reddit’s deal with OpenAI is confirmed. Here’s what it means for your posts and comments.
Reddit and OpenAI have confirmed a new deal which will mean ChatGPT can be trained using the platform’s content. So what does that mean for your posts and comments?

LanceDB, which counts Midjourney as a customer, is building databases for multimodal AI
Chang She, previously the VP of engineering at Tubi and a Cloudera veteran, has years of experience building data tooling and infrastructure. But when She began working in […]
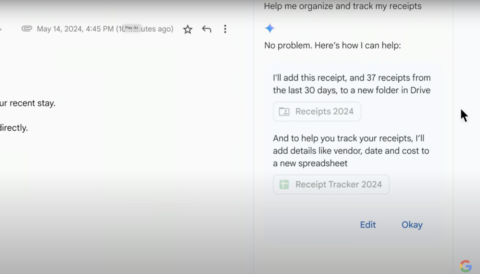
Google injects still more AI into Google Docs and other Workspace apps at Google I/O
Additional features from Google’s Gemini Pro 1.5 model will be added to Google Docs, Sheets, Slides, and others.
